Kedro
Kedro is an open-source Python framework that applies software engineering best-practice to data and machine-learning pipelines. You can use it, for example, to optimise the process of taking a machine learning model into a production environment. You can use Kedro to organise a single user project running on a local environment, or collaborate within a team on an enterprise-level project.
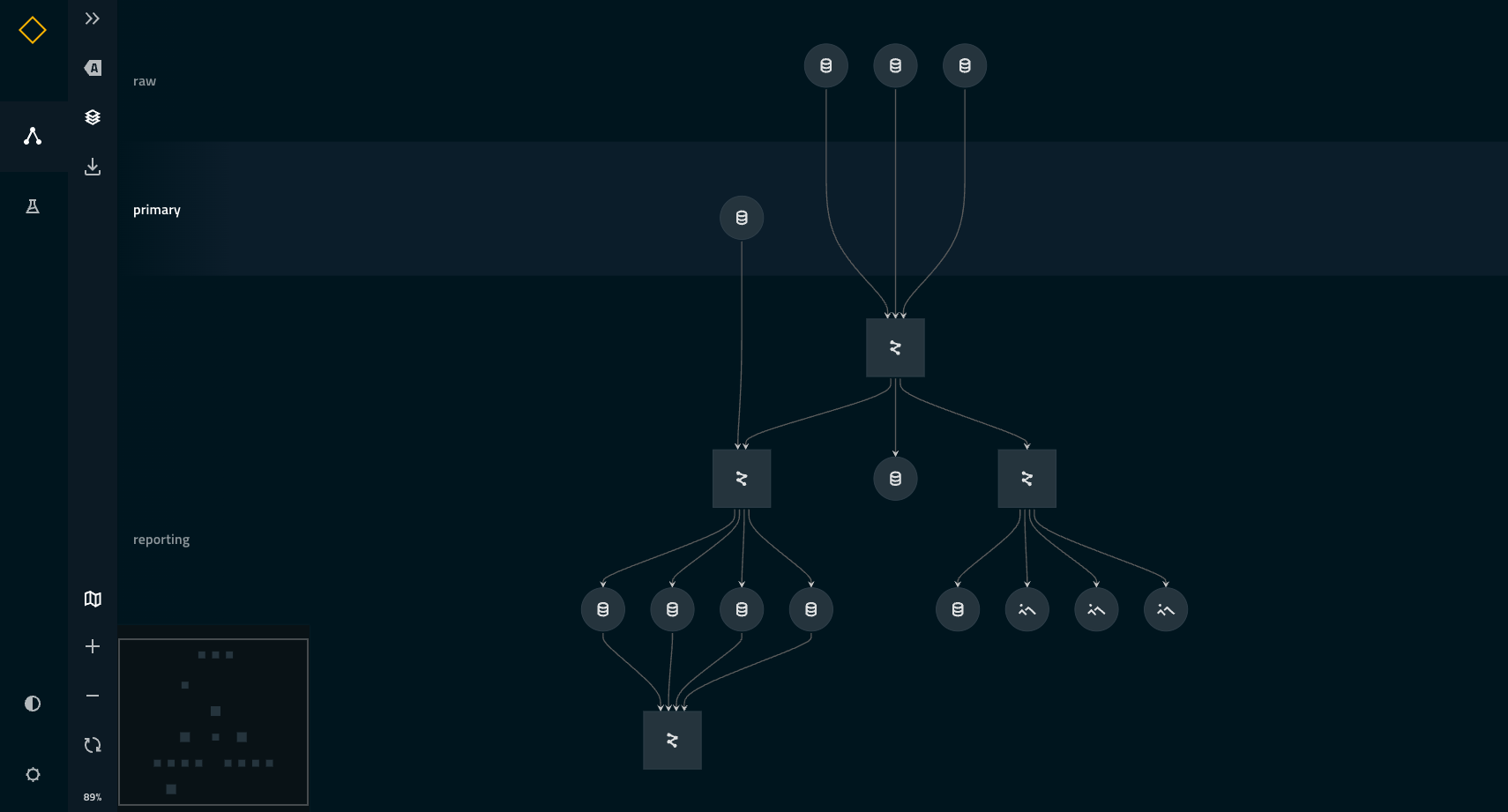
Kedro provides a standard approach so that you can:
- Worry less about how to write production-ready code,
- Spend more time building data pipelines that are robust, scalable, deployable, reproducible and versioned,
- Standardise the way that your team collaborates across your project.
I worked on Kedro project for nearly 2 years since before it was open sourced in June 2019, as well as various Kedro plugins such as Kedro-Viz. Kedro was donated to Linux Foundation in January 2022.
You can also find some of my public exposures about Kedro.
- Kedro 0.16.0 release article
- “Building a Production-level Data Pipeline Using Kedro” at Open Data Science Conference (DESC).