Synthetic Data for Deep Learning
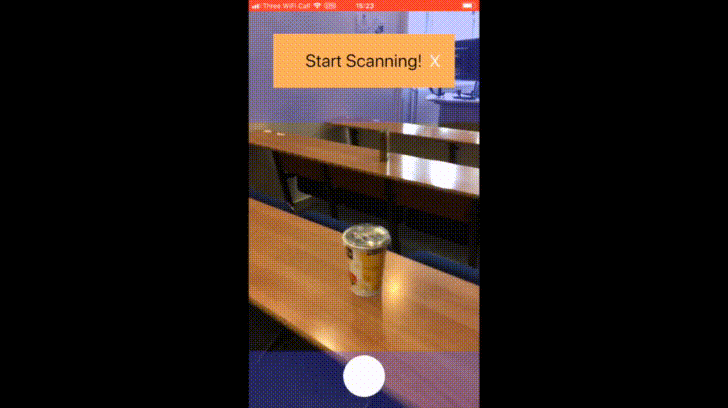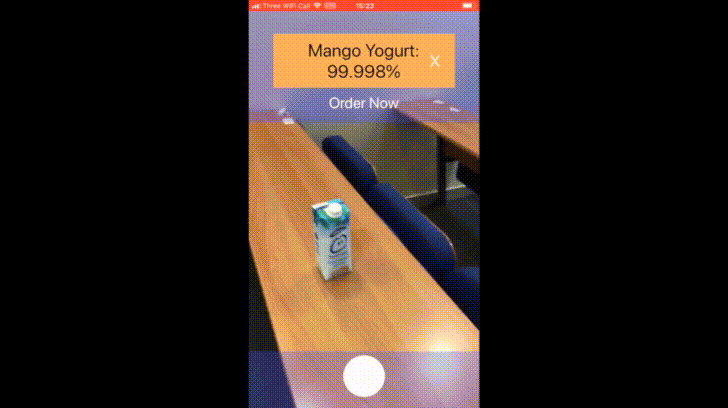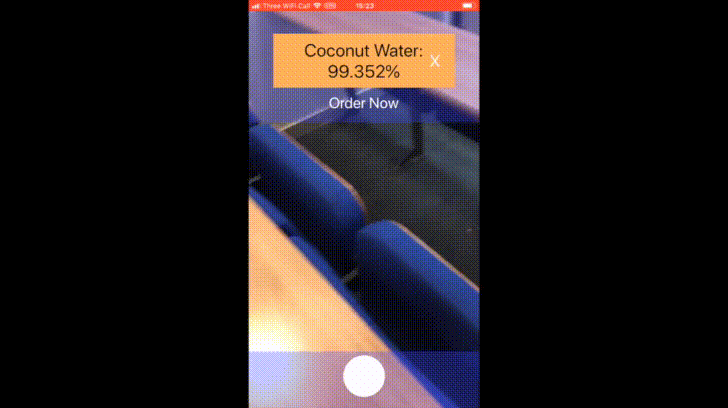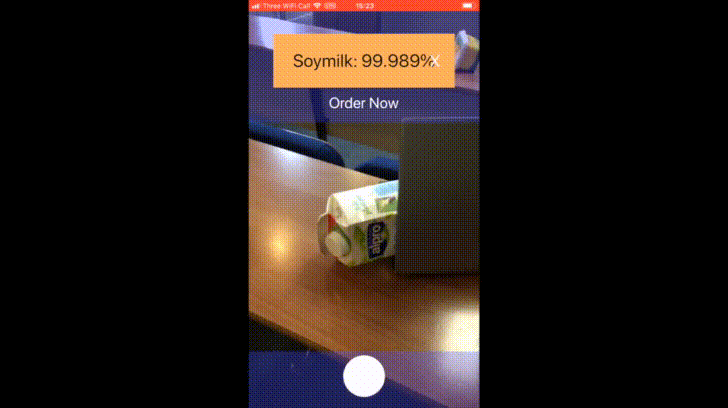

The availability of large image data sets has been a crucial factor in the success of deep learning-based classification and detection methods. Yet, while data sets for everyday objects are widely available, data for specific industrial use-cases (e.g., identifying packaged products in a warehouse) remains scarce. In such cases, the data sets have to be created from scratch, placing a crucial bottleneck on the deployment of deep learning techniques in industrial applications. We present work carried out in collaboration with a leading UK online supermarket, with the aim of creating a computer vision system capable of detecting and identifying unique supermarket products in a warehouse setting. To this end, we demonstrate a framework for using data synthesis to create an end-to-end deep learning pipeline, beginning with real-world objects and culminating in a trained model. Our method is based on the generation of a synthetic dataset from 3D models obtained by applying photogrammetry techniques to real-world objects. Using 100K synthetic images for 10 classes, an InceptionV3 convolutional neural network was trained, which achieved accuracy of 96% on a separately acquired test set of real supermarket product images. The image generation process supports automatic pixel annotation. This eliminates the prohibitively expensive manual annotation typically required for detection tasks. Based on this readily available data, a one-stage RetinaNet detector was trained on the synthetic, annotated images to produce a detector that can accurately localize and classify the specimen products in real-time.
Image Rendering
An interface between the generated 3D models and the input to the neural network was also necessary, using 3D models as the direct input to a classifier is is highly complex and would not achieve our goal of producing a scalable system for classifying 2D images.
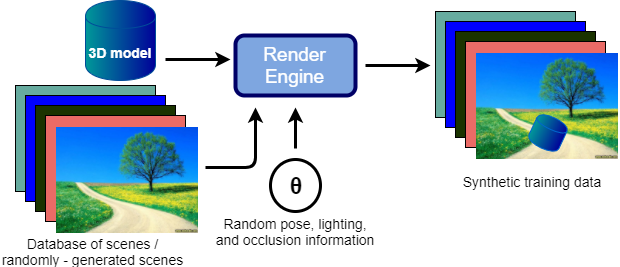
We developed an image rendering system that would take a 3D model as its input and produce a set of training images as its output, given a number of rendering parameters θ as shown in the figure above. The system would use the 3D model to produce multiple images showcasing the modeled product from all possible viewpoints, at different scale, under various lighting conditions, with different amounts of occlusion and with varying backgrounds.
A classifier trained on such generated data is expected to be robust to varying backgrounds, light conditions, occlusion, scale and pose. Furthermore, it allows the user to tailor the training set to a particular environment for which the image classifier will be deployed.
Final System Design
Our final system design shown in the figure below incorporated the key design choices describe above. These resulted in a custom neural network pipeline which goes from generation of 3D models to a customised evaluation suite used to optimise classification accuracy.
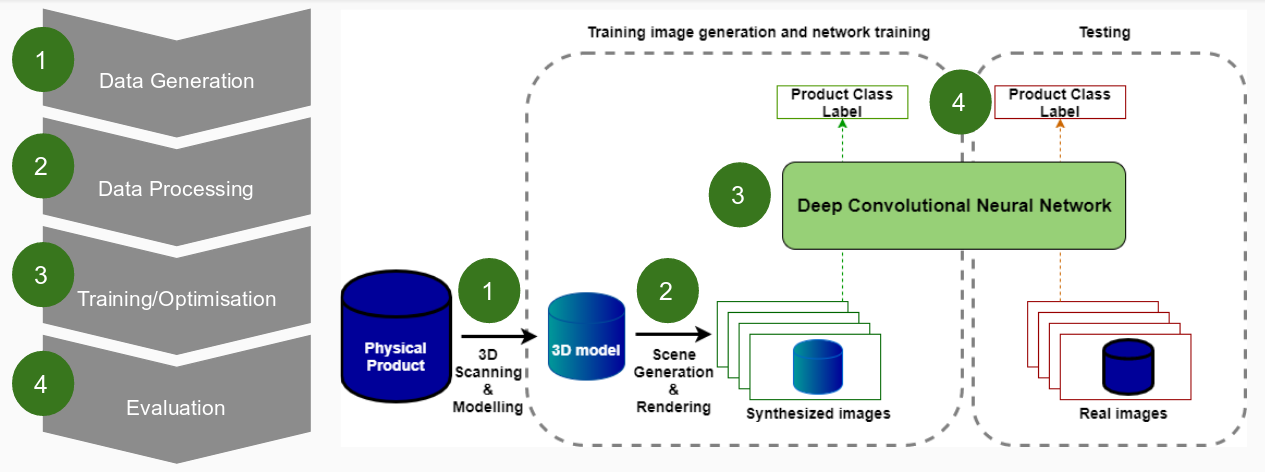
The individual component functionality is outlined as follows.
- Data Generation: provides 3D models of 10 products in .obj format. These models include textures and colour representations of the product and have to be of high enough quality to produce realistic product images in the next stage.
- Data Processing (Image Rendering): produces a specified number of training images for each product which vary product pose, lighting, background and occlusions. The type of background can be specified by the user. Both the rendered product and a background from a database are combined to create a unique training image in .jpeg format.
- Neural Network: the produced images are fed into a pre-trained convolutional neural network. The resulting retrained classifier should be able to classify real product images.
- Evaluation and Optimisation: the outlined approach to training data generation means that the training data can be tailored based on results. Therefore, a custom evaluation and optimization suite is required that is not provided in sufficient in detail in off-the-shelf solutions.