ILP Reinforcement Learning
Reinforcement Learning (RL) has been applied and proven to be successful in many domains. However, most of current RL methods face limitations, namely, low learning efficiency, inability to use abstract reasoning, and inability of transfer learning to similar environments. In order to tackle these shortcomings, we introduce a new learning approach called ILP(RL). ILP(RL) is based on Inductive Logic Programming (ILP) and Answer Set Programming (ASP) and learns a state transition with ILP and navigate through an environment using ASP. ILP(RL) learns a general concept of a state transition, called a hypothesis in an environment, and generates a plan for a sequence of actions to a destination. The learnt hypotheses is highly expressive and transferable to a similar environment. While there are a number of past papers that attempt to incorporate symbolic representation to RL problems in order to achieve efficient learning, there has not been any attempt of applying ASP-based ILP into a RL problem. We evaluated ILP(RL) in a various simple maze environments, and show that ILP(RL) finds an optimal policy faster than Q-learning. We also show that transfer learning of the learnt hypothesis successfully improves learning on a new but similar environment. While this preliminary ILP(RL) framework has limitations for scalability and flexibility, the results of the evaluations are promising, and open up an avenue for future research directions.
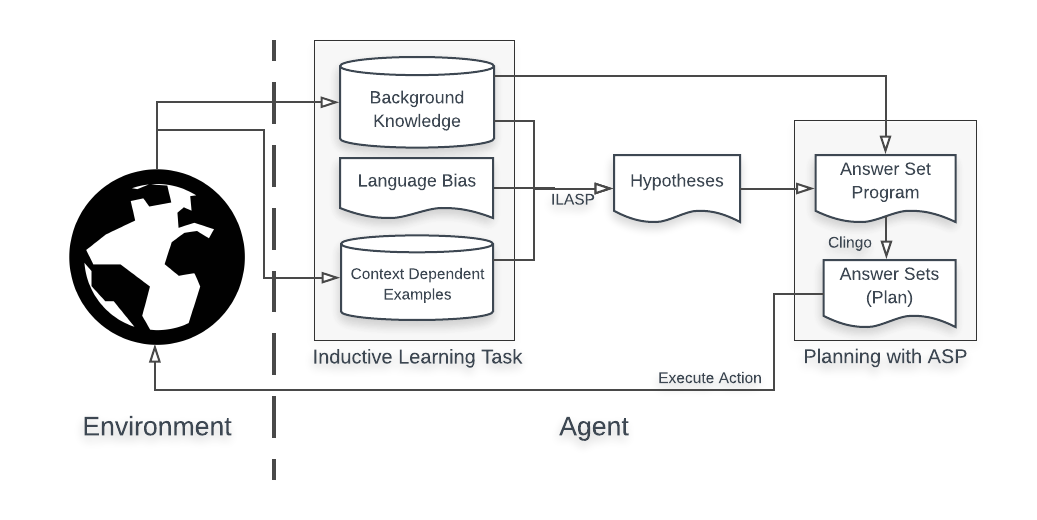
The overall architecture of ILP(RL), is shown in the figure above. ILP(RL) mainly consists of two components: inductive learning with ILASP(Inductive Learning of Answer Set Programs) and planning with ASP.
The first step is inductive learning with ILASP. An agent interacts with an unknown environment and receives state transition experiences as context dependent examples. Together with pre-defined background knowledge and language bias, these examples are used to inductively learn and improve hypotheses iteratively, which are state transition functions in the environment.
The second step is planning with ASP. The interaction with the environment gives the agent information about the environment, such as locations of walls or a terminal state. The agent remembers these information as background knowledge or context of the context dependent examples, and, together with the learnt hypotheses, uses them to make an action plan by solving an ASP program. The plan is a sequence of actions and it navigates the agent in the environment.
The agent iteratively executes this cycle in order to learn and improve the hypotheses as well as an action planning.
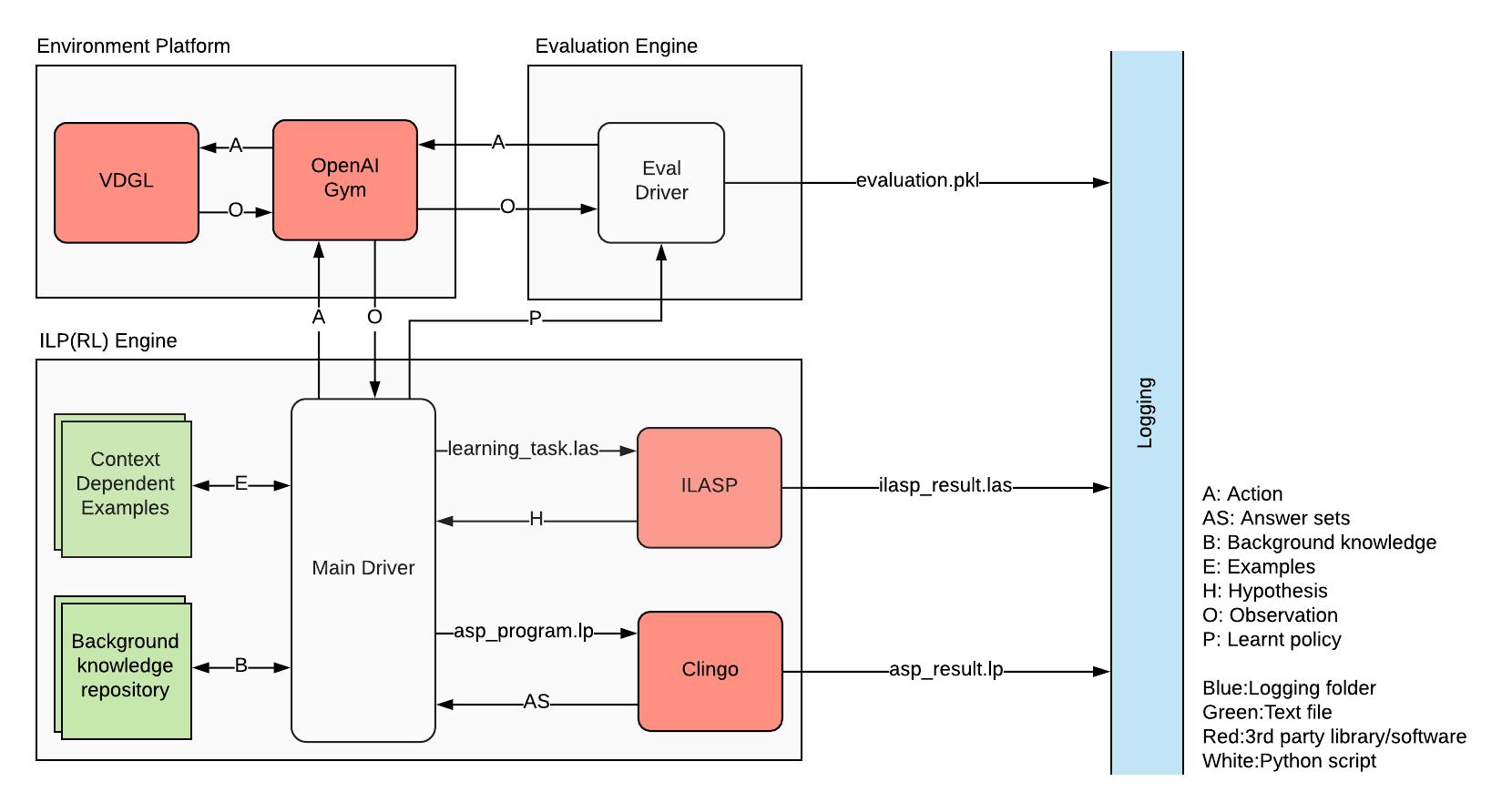
We divide our implementation of the design outline into three separate software components: ILP(RL) Engine, Environment Platform and Evaluation Engine. The overview of our software implementation is shown in the data flow diagram in the figure above.
ILP(RL) Engine is our main framework shown in Framework. The main driver constructs the necessary files, such as a learning task and an ASP program, and handles the communications by sending input and output among third-party software and libraries as well as executing their programs: ILASP, Clingo and the environment platform including the Video Game Definition Language (VDGL) and OpenAI Gym. The main driver is also responsible for I/O operation for context dependent examples as well as background knowledge, both are being accumulated in text files. Eval Driver is another Python script that executes the evaluation of ILP(RL) as well as a benchmark RL algorithm for evaluations. Finally, all the results of inductive learning with ILASP, ASP planning and evaluation are recorded in Logging folder.